
WebEquipe PDF Search
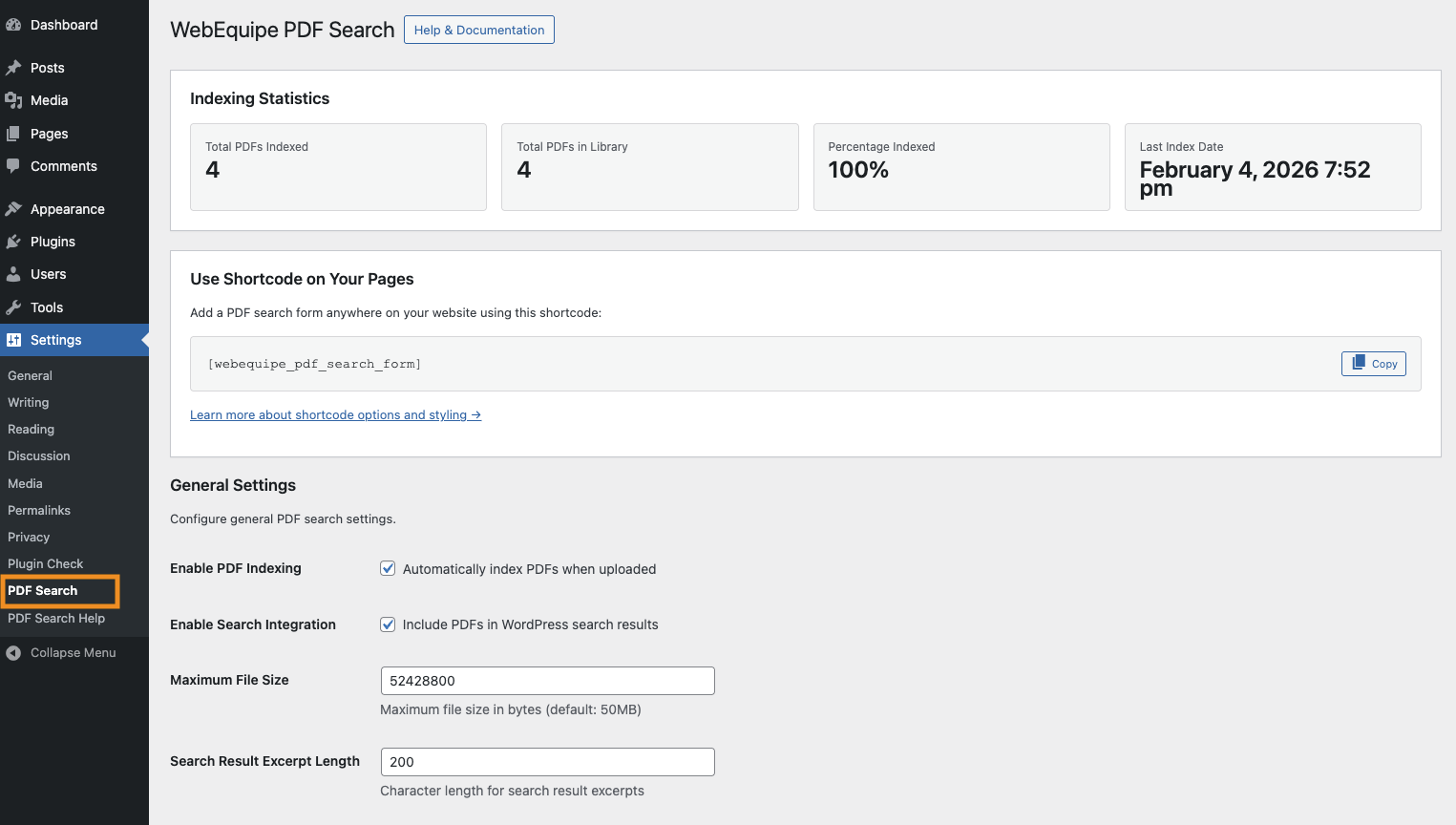
Settings page – indexing stats, options, shortcode, and PDF list
WebEquipe PDF Search indexes your PDF files and makes their text searchable. When visitors search your site, they see results from both your posts/pages and the content inside your PDFs.
Video
Watch the setup and usage guide:
Supported PDFs
- Works with: Standard, text-based PDFs (the kind you create or export from Word, Google Docs, etc.). File size default 50MB, configurable up to 500MB in settings.
- Does not work with: Scanned PDFs or image-only PDFs (no extractable text)—use OCR elsewhere first. Password-protected PDFs cannot be indexed.
Keep Private PDFs Out of Search
Need to hide or protect certain PDFs? Use Exclude so a PDF is never indexed and never appears in search—even when you run “Re-index All PDFs” or bulk index. Excluded PDFs stay in your Media Library; they just won’t be searchable. Use Include later to allow indexing again. You can exclude or include PDFs from the Media Library or from Settings PDF Search (Manage PDFs).
How to Use
- Install and activate the plugin.
- Go to Settings PDF Search.
- Click Re-index All PDFs to index existing PDFs (new uploads are indexed automatically by default).
- Use your site’s search or add the shortcode
[webequipe_pdf_search_form]on a page—PDFs will appear in results.
Existing PDFs need to be indexed once; after that, new uploads can be indexed automatically (optional in settings). To hide specific PDFs from search, use Exclude on them (Media Library or Settings PDF Search Manage PDFs).
Settings at a Glance
All options are under Settings PDF Search:
- General – Turn indexing on/off, include PDFs in WordPress search, maximum file size (50MB default), excerpt length.
- Indexing options – Batch size for re-indexing.
- Search display options – Show or hide PDF icon, file size, page count, last updated date, and thumbnail preview in search results.
- Advanced – Debug logging, memory/timeout for large PDFs, background processing, delete data on uninstall.
Full details and shortcode options: Settings PDF Search Help.
What You Can Do
- Full-text search – Search inside PDF content, not just filenames.
- Control each PDF – Index, unindex, or exclude from the Media Library or the PDF list on the settings page.
- Bulk actions – Index, unindex, include, or exclude multiple PDFs at once.
- Search display – Show PDF icon, file size, page count, and excerpts (configurable in settings).
- Shortcode – Add a PDF search form with
[webequipe_pdf_search_form](see Settings PDF Search Help for options). - Background processing – Large PDFs are processed in the background to avoid timeouts.
Troubleshooting
PDFs not appearing in search
Ensure PDFs are indexed (Media Library “Search Indexed” column), “Enable Search Integration” is on in Settings PDF Search, and the PDF is not excluded. See the FAQ for more.
Indexing fails or times out
Use Settings PDF Search Advanced: enable “Background Processing” for large PDFs. Ensure your server PHP memory_limit and max_execution_time are sufficient for very large files (see Help for details). Reduce “Batch Size” if re-indexing many PDFs at once.
Other issues
See the FAQ above and Settings PDF Search Help for full documentation.
Privacy
The plugin stores extracted PDF text and metadata in a custom database table and a compressed backup in WordPress post meta for PDF attachments. If debug logging is enabled, it stores recent log entries in a WordPress option. It does not collect or send visitor data. If your PDFs contain personal or sensitive information, that content is in the index; mention this in your privacy policy if required.
Third-Party Libraries
- smalot/pdfparser (LGPL-3.0) – PDF text extraction
- symfony/polyfill-mbstring (MIT) – multibyte string support
Credits
Developed by WebEquipe. Uses smalot/pdfparser for PDF text extraction.
Support
- Support: https://wordpress.org/support/plugin/webequipe-pdf-search